







У рекламі Apple собаки знову можуть грати після протезування
28 Вересня, 2023 13:29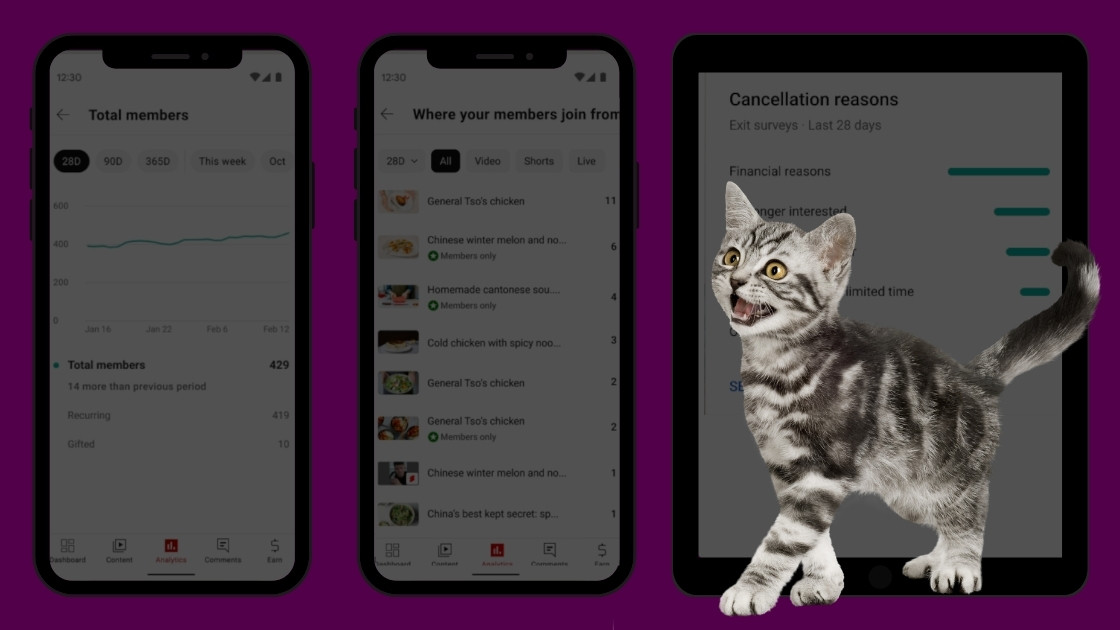
YouTube запускає нову аналітику про те, чому підписники скасовують підписку на канал
2 Жовтня, 2023 21:24У рекламі Apple собаки знову можуть грати після протезування
28 Вересня, 2023 13:29YouTube запускає нову аналітику про те, чому підписники скасовують підписку на канал
2 Жовтня, 2023 21:24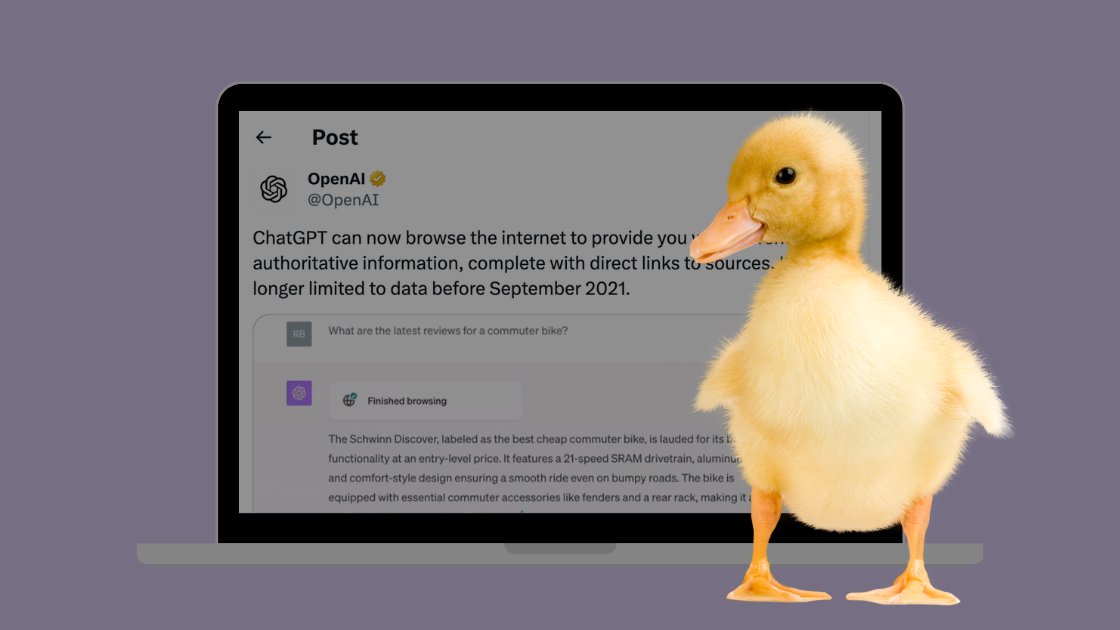
Невже це правда, але OpenAI справді додає веб-перегляд ChatGPT у реальному часі, і пояснює, як відтепер буде відповідати на всі наші питання за допомогою новинок.
Це може стати великим оновленням для користувачів ChatGPT, оскільки виробник OpenAI оголосив, що генеративна платформа штучного інтелекту тепер може переглядати веб-сторінки в реальному часі, а це означає, що її відповіді більше не будуть обмежені датою.
ChatGPT буде мати доступ до інформації онлайн джерел в реальному часі
ChatGPT can now browse the internet to provide you with current and authoritative information, complete with direct links to sources. It is no longer limited to data before September 2021. pic.twitter.com/pyj8a9HWkB
— OpenAI (@OpenAI) September 27, 2023
Як ви можете бачити в цьому пості OpenAI, ChatGPT тепер зможе надавати найновішу інформацію для покращення своїх відповідей, що забезпечить, в ідеалі, точніші результати або, принаймні, більше відображає останні події та зміни.
До цього часу ChatGPT в безкоштовній версії послуговувався базою знань, яка востаннє оновлювалася в червні 2021 року, що дуже впливало на актуальність інформації, яку він використовував у своїх відповідях.
Відповідно до OpenAI: «Перегляд особливо корисний для завдань, які вимагають актуальної інформації, як-от допомога в технічних дослідженнях, вибір велосипеда або планування відпустки.»
Однак не всі веб-сайти будуть доступні для системи OpenAI.
Надавши веб-адміністраторам можливість відмовитися від збирання даних, повідомивши про це у своєму файлі robots.txt, багато видавців, особливо відомі сайти, зробили саме це, і оскільки інструменти штучного інтелекту знайдуть більше використання, ви можете очікувати більше веб-сайтів, які оновлять свою структуру, щоб заблокувати отримання OpenAI інформації з їхнього ресурсу.
Але знову ж таки, мільйони інших, ймовірно, цього не зроблять, а це означатиме, що OpenAI тепер матиме доступ до широкого діапазону живих вхідних даних, що забезпечить більше контексту для його відповідей.
OpenAI повідомляє, що веб-перегляд стане доступним для користувачів Plus і Enterprise зі вчорашнього дня, а подальше розширення буде незабаром.
Голосовий пошук в ChatGPT
На додаток до цього, OpenAI також розгортає нові опції голосового пошуку та пошуку зображень у ChatGPT.
«Голос і зображення дають вам більше можливостей використовувати ChatGPT у своєму житті. Сфотографуйте пам’ятку під час подорожі та живо обговоріть, що в ній цікавого. Коли ви вдома, сфотографуйте свій холодильник і комору, щоб зрозуміти, що на вечерю (і поставте додаткові запитання, щоб отримати покроковий рецепт). Після вечері допоможіть своїй дитині розв'язувати математичну задачу, сфотографувавши, обвівши набір задач, і попросіть її поділитися підказками з вами обом».
Тож тепер, замість того, щоб просто вводити текст, ви зможете задати ChatGPT свій запит напряму, і відповідь буде прочитана вам автоматично.
Реакція Google на це оновлення ChatGPT
Одразу після того, як OpenAI оголосив, що веб-адміністратори зможуть блокувати його системам сканування їхнього контенту, оновивши файл robots.txt свого сайту, Google також прагне надати веб-менеджерам більше контролю над їхніми даними та чи дозволять вони відкривати свій контент для генеративного пошуку ШІ.
Як пояснив Google: «Сьогодні ми анонсуємо Google-Extended, новий засіб керування, який веб-видавці можуть використовувати, щоб керувати тим, чи допомагають їхні сайти вдосконалювати генеративні API Bard і Vertex AI, включаючи майбутні покоління моделей, які забезпечують ці продукти. Використовуючи Google-Extended для контролю доступу до контенту на сайті, адміністратор веб-сайту може вибрати, чи допомагати цим моделям штучного інтелекту з часом ставати точнішими та ефективнішими».
Це дуже схоже на формулювання, яке використовував OpenAI, намагаючись змусити більше сайтів надавати доступ до даних з обіцянкою покращення своїх моделей.
Дійсно, видання SMT у документації OpenAI знайшли пояснення, що: "Отриманий контент використовується лише в процесі навчання, щоб навчити наших моделей, як відповідати на запити користувачів із цим вмістом (тобто, щоб зробити наші моделі кращими в перегляді), а не для того, щоб покращити наші моделі у створенні відповідей".
Що зараз взагалі відбувається?
Очевидно, і Google, і OpenAI хочуть продовжувати отримувати якомога більше даних з відкритого Інтернету. Але здатність блокувати моделі штучного інтелекту в контенті вже застосовувалася багатьма великими видавцями та творцями, щоб захистити авторські права та запобігти копіюванню їх роботи генеративними системами штучного інтелекту.
І з розгортанням дискусій навколо регулювання штучного інтелекту великі гравці можуть вплинути на посилення дотримання наборів даних, які використовуються для створення генеративних моделей штучного інтелекту.
Але це може відбуватися вже занадто пізно, адже, наприклад, OpenAI вже створює свої моделі GPT (до GPT-4) на основі даних, отриманих з Інтернету до 2021 року. Тому деякі великі мовні моделі (LLM) уже були створені раніше ці дозволи були оприлюднені. Але, рухаючись вперед, можливо, усі LLM матимуть значно менше веб-сайтів, до яких вони зможуть отримати доступ для створення своїх генеративних систем ШІ.
Зараз цікаво спостерігати за цими змінами й дочекатися, що буде відбуватися з SEO через нову логіку онлайн-пошуку та новий порядок видачі результатів для користувачів.



{kind=link}
{kind=link}
{kind=link}